기타 InstructLab이 어떻게 Gen AI를 위한 접근 가능한 모델 미세 조정을 가능하게 하는지
페이지 정보

본문
InstructLab이 어떻게 Gen AI를 위한 접근 가능한 모델 미세 조정을 가능하게 하는지

특정 사용 사례에 맞게 대규모 언어 모델(LLM)을 조정하려면 전통적으로 광범위한 리소스와 전문 지식이 필요합니다. Gartner는 2026년까지 80% 이상의 기업이 생성적 AI 지원 애플리케이션을 배포할 것이라고 말하지만 , 이러한 모델을 도메인별 작업에 맞게 사용자 지정하는 과제는 여전히 중요합니다. IBM과 Red Hat이 개발한 오픈소스 프로젝트인 InstructLab은 LLM 튜닝을 민주화하여 이러한 격차를 해소하는 것을 목표로 합니다. InstructLab이 개발자(및 도메인 전문가)가 소비자 등급 하드웨어에서도 언어 모델을 효율적으로 개선하고 전문화하여 산업 전반에 걸쳐 맞춤형 AI 솔루션 도입을 가속화할 수 있는 방법을 살펴보겠습니다. 이 기사에는 Legare Kerrison 과 Cedric Clyburn이 WeAreDevelopers World Congress 2024 에서 발표한 컨퍼런스 프레젠테이션이 함께 제공되며 , 아래에서 볼 수 있습니다.
LLM의 한계는 무엇입니까?
인상적인 역량에도 불구하고 현재 LLM은 전문 분야에서의 효과를 저해하는 몇 가지 중요한 한계에 직면해 있습니다.
- 지식 차단 : 모델은 훈련 데이터에 의해 제약을 받으며, 이로 인해 종종 오래된 정보가 제공되기도 합니다.
- 투명성 부족 : 이러한 모델이 어떻게 결론을 도출하는지가 불분명한 경우가 많아 신뢰 문제가 발생할 수 있습니다.
- 거짓 정보 : LLM은 설득력 있지만 부정확한 답변을 낳을 수 있습니다 .
- 도메인 지식 부족 : 일반 모델은 특정 산업에 필요한 구체적인 지식이 없을 수 있습니다. LLM에는 제한된 양의 기업 지식만 표현됩니다.
- 설명 가능성 : 모델이 특정한 결정을 내린 이유를 이해하는 것은 어려울 수 있습니다.
이러한 과제는 모델을 기대치에 더 잘 맞추기 위한 보다 타겟팅된 접근 방식의 필요성과 사용 사례를 강조합니다. 사전 훈련되고 일반적인 LLM이 바로 요구 사항을 충족하지 못하는 경우, 전반적인 효과성, 정확성 및 성능을 개선하기 위해 어떤 기술을 사용할 수 있습니까?
생성 AI 모델을 강화하는 기술
대규모 언어 모델의 한계를 해결하기 위해 몇 가지 핵심 기술이 등장했습니다.
- 사전 훈련 및 미세 조정: 대부분의 회사는 기초 모델의 사전 훈련에 참여할 컴퓨팅 리소스가 없지만 미세 조정은 일반적으로 기존 오픈 소스 모델을 가져와 특정 사용 사례에 대한 추가 훈련을 수행하는 것을 포함합니다. 효과적이기는 하지만 종종 리소스 집약적이며 상당한 컴퓨팅 파워와 시간이 필요합니다. 이 프로세스는 일반적으로 원래 모델을 포킹하는 것을 수반하므로 개선 사항을 주 모델 버전에 다시 통합하는 것이 어려울 수 있습니다.
- 접지(검색 증강 생성) : 이는 특정 작업을 수행하기 위한 관련 외부 데이터를 모델에 제공합니다. 이전 방법과 달리 RAG는 실제로 기본 모델을 개선하지 않습니다. 대신 런타임에 관련 정보를 검색하여 통합하여 모델의 지식을 보완합니다. 이 접근 방식은 특정 쿼리에 대한 정확도를 향상시킬 수 있지만 본질적으로 모델을 더 유능하거나 지식이 풍부하게 만들지는 않습니다.
그림 1은 이러한 향상 기술을 보여줍니다.
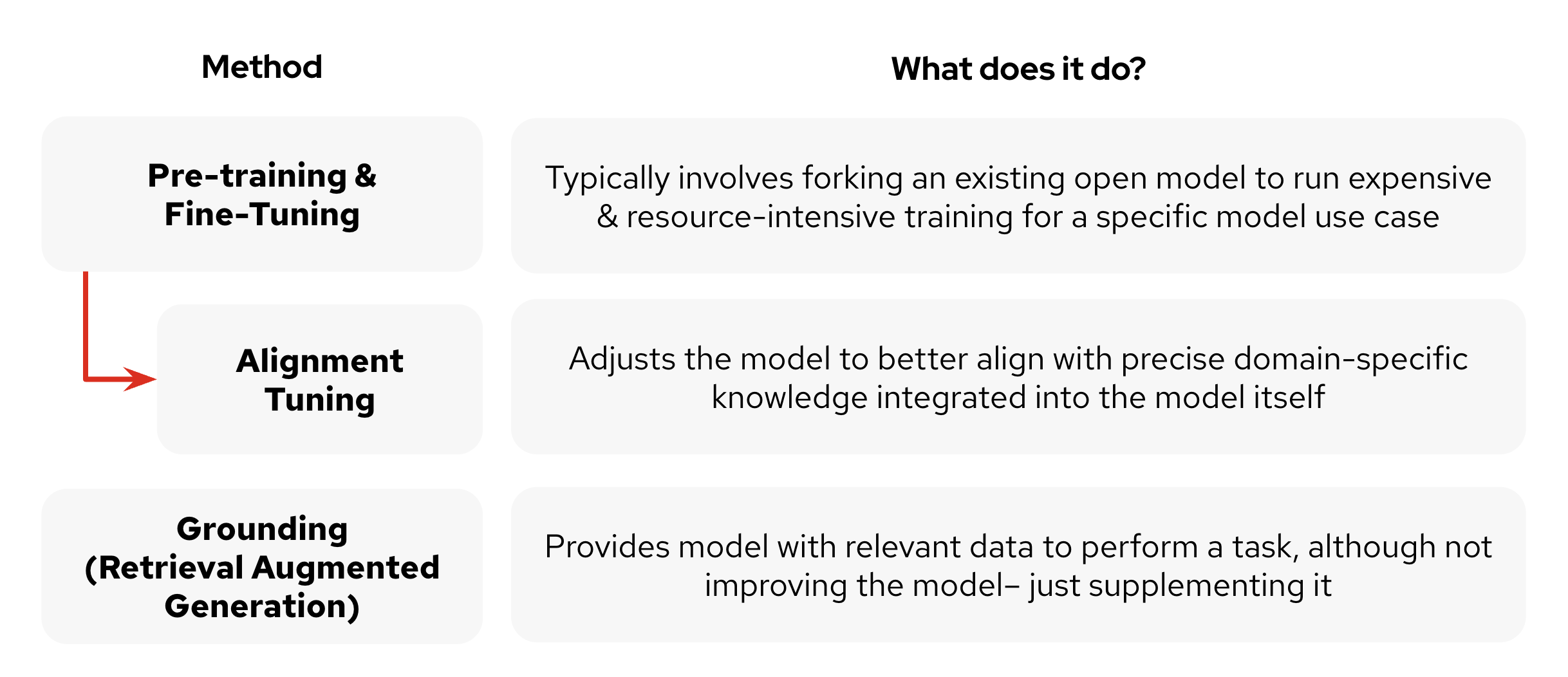 그림 1: 대규모 언어 모델의 출력과 정확도를 향상시키는 다양한 방법.
그림 1: 대규모 언어 모델의 출력과 정확도를 향상시키는 다양한 방법.이러한 기술은 뚜렷한 이점을 제공하며 특히 다양한 시나리오(또는 미세 조정 및 RAG의 경우 결합)에 적합할 수 있습니다. 미세 조정은 작업별 최적화에 뛰어나지만 전통적으로 리소스 비용이 더 높습니다. RAG는 유연성과 최신 정보를 제공하지만 효율적인 파이프라인이 필요하며 기본 모델을 개선하는 것이 아니라 정보로 보완하는 것에 불과합니다.
사례 연구: 기초 모델이 비용에 미치는 영향
모델을 개선하는 데 사용된 방법과 관계없이 기초 모델을 선택하면 AI 솔루션의 전반적인 비용, 성능 및 효율성에 상당한 영향을 미칠 수 있습니다. IBM Watson의 사례 연구 에서 박사 학위를 취득한 Maryam Ashoori 는 선택한 기본 모델이 비용에 미치는 영향을 설명합니다. 직원이 700명인 회사의 500단어 회의 요약을 생성하기 위해 LLM을 선택하고 각 직원이 매일 5회의 30분 회의에 참석하고 각 회의에 직원이 3명씩 있다고 가정한다고 가정합니다. 52B 매개변수 일반 용도 LMM으로 이를 수행하려면 요약당 0.09달러가 들고, 하루에 105달러, 연간 38,325달러가 듭니다. 대신 Watsonx.AI 에 호스팅된 더 작은 3B 매개변수 모델을 미세 조정했다면 요약당 $0.0039996이 들고, 연간 총 $1,702.19에 일회성 $1,152 모델 조정 비용이 더해져 연간 $2,854가 됩니다. 즉, 그림 2에서 볼 수 있듯이 미세 조정된 LLM을 사용하면 대형 일반 LLM을 사용하는 것보다 14배 더 저렴하다는 의미입니다.
 그림 2: 모델 선택과 훈련이 비용에 미치는 영향.
그림 2: 모델 선택과 훈련이 비용에 미치는 영향.접근 가능한 모델 미세 조정을 위해 InstructLab 사용
InstructLab은 LLM 미세 조정을 보다 쉽게 접근할 수 있도록 하는 강력한 프레임워크를 제공하며 , 데이터 과학 배경이 없는 사람들을 위해 모델의 조정 및 개발을 민주화하도록 설계되었습니다. InstructLab의 프로세스는 교사와 비평가 모델이 함께 작업하여 AI를 훈련하고, 모델이 특정 도메인에 맞게 조정되도록 보장하고, 정확도와 관련성을 개선하는 것과 유사합니다. 이는 그림 3에 자세히 설명된 몇 가지 핵심 구성 요소를 통해 가능합니다.
- 분류 기반 데이터 큐레이션: 이 프로젝트는 기술과 지식을 구조화된 폴더 스타일 디렉토리 로 정리하여 모델 기능의 특정 격차를 식별하고 해결하는 데 도움이 됩니다.
- 대규모 합성 데이터 생성: InstructLab은 사용자가 정의한 초기 사례를 기반으로 다양하고 고품질의 추가 훈련 데이터를 생성합니다.
- 다단계 교육: 새로운 지식과 기술은 여러 계층의 단계로 데이터에 통합됩니다.
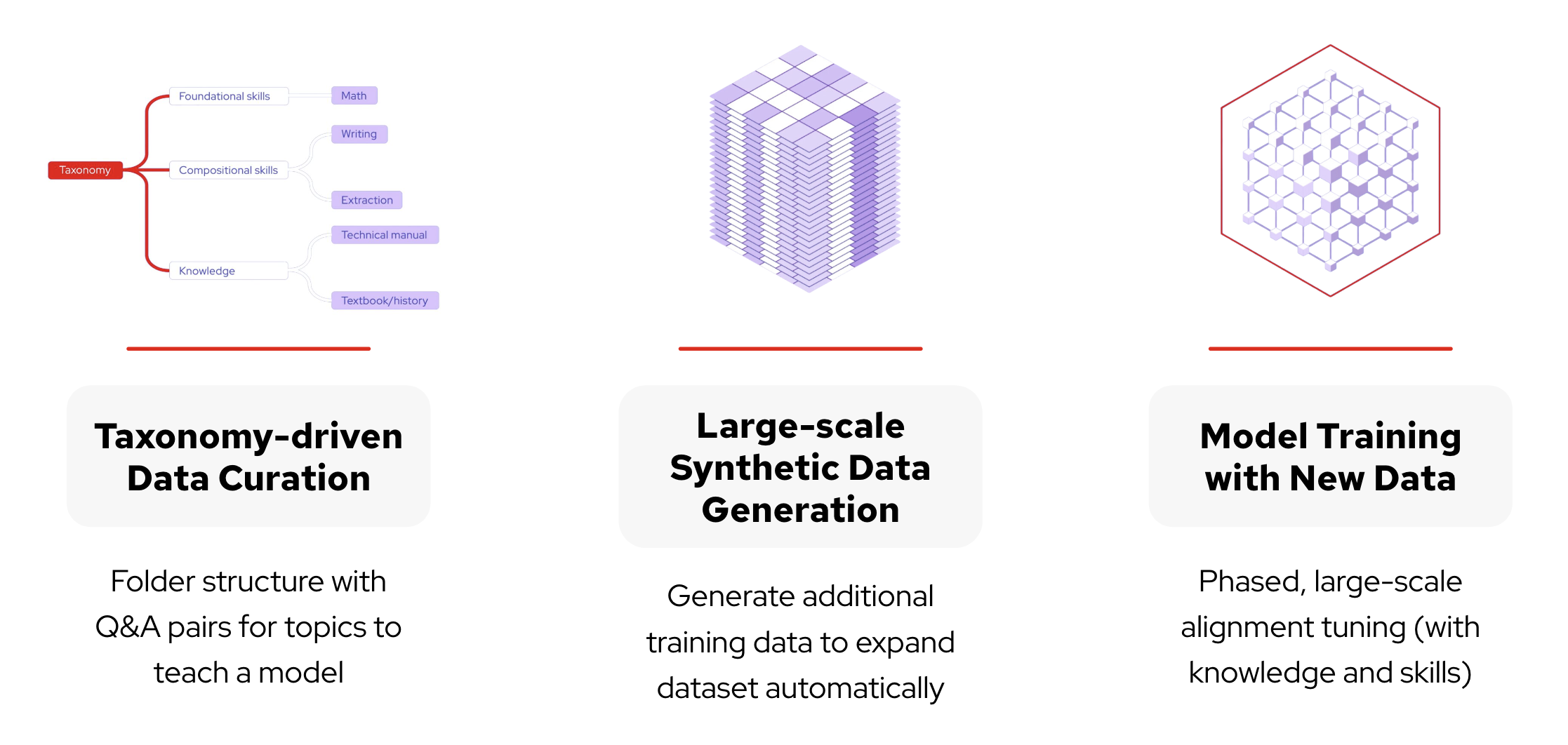 그림 3: InstructLab 프로젝트를 구성하는 주요 구성 요소.
그림 3: InstructLab 프로젝트를 구성하는 주요 구성 요소.개인이 특정 사용 사례에 대한 모델을 훈련하면 풀 리퀘스트 분류 시스템을 통해 훈련 데이터를 Instructlab의 커뮤니티 모델 과 통합할 수 있습니다 . 이 오픈 소스 방법론을 통해 모든 사람이 모델 기여 및 개발의 미래에 대해 의견을 제시할 수 있으며, 다양한 전문 지식과 관점이 AI 개발을 형성할 수 있는 협업 환경을 조성합니다.
결론
AI가 계속 진화함에 따라 InstructLab 과 같은 기술은 최첨단 AI 연구와 실용적이고 기업에 적합한 애플리케이션 간의 격차를 메우고 있습니다. LLM 튜닝을 개별 사용자와 조직이 더 쉽게 사용할 수 있도록 함으로써 모델에 대한 일부 제한을 극복하고 보다 정확하고 신뢰할 수 있으며 특화된 AI 솔루션을 만들 수 있습니다.
우리는 AI의 미래가 협력적이고 개방적이라고 믿습니다 . 자신의 모델을 미세 조정하든 다른 사람들이 사용할 수 있는 공유 커뮤니티 모델에 기여하든, 여러분은 AI를 민주화하는 데 도움을 주고 있습니다. InstructLab을 시작하려면 GitHub 저장소에서 시스템에 대한 설치 지침을 확인하고 X 와 LinkedIn 에서 InstructLab을 팔로우하여 프로젝트에 대한 업데이트를 받으세요!
댓글목록
등록된 댓글이 없습니다.
